ORM API¶
- Object Relational Mapping module:
Hierarchical structure
Constraints consistency and validation
Object metadata depends on its status
Optimised processing by complex query (multiple actions at once)
Default field values
Permissions optimisation
Persistent object: DB postgresql
Data conversion
Multi-level caching system
Two different inheritance mechanisms
- Rich set of field types:
classical (varchar, integer, boolean, …)
relational (one2many, many2one, many2many)
functional
Models¶
Model fields are defined as attributes on the model itself:
from flectra import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
Warning
this means you cannot define a field and a method with the same name, the last one will silently overwrite the former ones.
By default, the field’s label (user-visible name) is a capitalized version of
the field name, this can be overridden with the string parameter.
field2 = fields.Integer(string="Field Label")
For the list of field types and parameters, see the fields reference.
Default values are defined as parameters on fields, either as a value:
name = fields.Char(default="a value")
or as a function called to compute the default value, which should return that value:
def _default_name(self):
return self.get_value()
name = fields.Char(default=lambda self: self._default_name())
API
- class flectra.models.BaseModel[source]¶
Base class for Flectra models.
Flectra models are created by inheriting one of the following:
Modelfor regular database-persisted modelsTransientModelfor temporary data, stored in the database but automatically vacuumed every so oftenAbstractModelfor abstract super classes meant to be shared by multiple inheriting models
The system automatically instantiates every model once per database. Those instances represent the available models on each database, and depend on which modules are installed on that database. The actual class of each instance is built from the Python classes that create and inherit from the corresponding model.
Every model instance is a “recordset”, i.e., an ordered collection of records of the model. Recordsets are returned by methods like
browse(),search(), or field accesses. Records have no explicit representation: a record is represented as a recordset of one record.To create a class that should not be instantiated, the
_registerattribute may be set to False.- _auto = False¶
Whether a database table should be created. If set to
False, overrideinit()to create the database table.Automatically defaults to
TrueforModelandTransientModel,FalseforAbstractModel.Tip
To create a model without any table, inherit from
AbstractModel.
- _log_access¶
Whether the ORM should automatically generate and update the Access Log fields.
Defaults to whatever value was set for
_auto.
- _sequence = None¶
SQL sequence to use for ID field
- _sql_constraints = []¶
SQL constraints [(name, sql_def, message)]
- _register = True¶
registry visibility
- _abstract = True¶
Whether the model is abstract.
See also
- _transient = False¶
Whether the model is transient.
See also
- _name = None¶
the model name (in dot-notation, module namespace)
- _description = None¶
the model’s informal name
- _inherits = {}¶
dictionary {‘parent_model’: ‘m2o_field’} mapping the _name of the parent business objects to the names of the corresponding foreign key fields to use:
_inherits = { 'a.model': 'a_field_id', 'b.model': 'b_field_id' }
implements composition-based inheritance: the new model exposes all the fields of the inherited models but stores none of them: the values themselves remain stored on the linked record.
Warning
if multiple fields with the same name are defined in the
_inherits-ed models, the inherited field will correspond to the last one (in the inherits list order).
- _rec_name = None¶
field to use for labeling records, default:
name
- _order = 'id'¶
default order field for searching results
- _check_company_auto = False¶
On write and create, call
_check_companyto ensure companies consistency on the relational fields havingcheck_company=Trueas attribute.
- _parent_name = 'parent_id'¶
the many2one field used as parent field
- _parent_store = False¶
set to True to compute parent_path field.
Alongside a
parent_pathfield, sets up an indexed storage of the tree structure of records, to enable faster hierarchical queries on the records of the current model using thechild_ofandparent_ofdomain operators.
- _date_name = 'date'¶
field to use for default calendar view
- _fold_name = 'fold'¶
field to determine folded groups in kanban views
AbstractModel¶
- flectra.models.AbstractModel[source]¶
alias of
flectra.models.BaseModel
Model¶
- class flectra.models.Model[source]¶
Main super-class for regular database-persisted Flectra models.
Flectra models are created by inheriting from this class:
class user(Model): ...
The system will later instantiate the class once per database (on which the class’ module is installed).
- _auto = True¶
Whether a database table should be created. If set to
False, overrideinit()to create the database table.Automatically defaults to
TrueforModelandTransientModel,FalseforAbstractModel.Tip
To create a model without any table, inherit from
AbstractModel.
- _abstract = False¶
Whether the model is abstract.
See also
- _transient = False¶
Whether the model is transient.
See also
TransientModel¶
- class flectra.models.TransientModel[source]¶
Model super-class for transient records, meant to be temporarily persistent, and regularly vacuum-cleaned.
A TransientModel has a simplified access rights management, all users can create new records, and may only access the records they created. The superuser has unrestricted access to all TransientModel records.
- _auto = True¶
Whether a database table should be created. If set to
False, overrideinit()to create the database table.Automatically defaults to
TrueforModelandTransientModel,FalseforAbstractModel.Tip
To create a model without any table, inherit from
AbstractModel.
- _abstract = False¶
Whether the model is abstract.
See also
- _transient = True¶
Whether the model is transient.
See also
Fields¶
- class flectra.fields.Field[source]¶
The field descriptor contains the field definition, and manages accesses and assignments of the corresponding field on records. The following attributes may be provided when instanciating a field:
- Parameters
string (str) – the label of the field seen by users; if not set, the ORM takes the field name in the class (capitalized).
help (str) – the tooltip of the field seen by users
invisible – whether the field is invisible (boolean, by default
False)readonly (bool) –
whether the field is readonly (default:
False)This only has an impact on the UI. Any field assignation in code will work (if the field is a stored field or an inversable one).
required (bool) – whether the value of the field is required (default:
False)index (bool) – whether the field is indexed in database. Note: no effect on non-stored and virtual fields. (default:
False)default (value or callable) – the default value for the field; this is either a static value, or a function taking a recordset and returning a value; use
default=Noneto discard default values for the fieldstates (dict) –
a dictionary mapping state values to lists of UI attribute-value pairs; possible attributes are:
readonly,required,invisible.Warning
Any state-based condition requires the
statefield value to be available on the client-side UI. This is typically done by including it in the relevant views, possibly made invisible if not relevant for the end-user.groups (str) – comma-separated list of group xml ids (string); this restricts the field access to the users of the given groups only
company_dependent (bool) –
whether the field value is dependent of the current company;
The value isn’t stored on the model table. It is registered as
ir.property. When the value of the company_dependent field is needed, anir.propertyis searched, linked to the current company (and current record if one property exists).If the value is changed on the record, it either modifies the existing property for the current record (if one exists), or creates a new one for the current company and res_id.
If the value is changed on the company side, it will impact all records on which the value hasn’t been changed.
copy (bool) – whether the field value should be copied when the record is duplicated (default:
Truefor normal fields,Falseforone2manyand computed fields, including property fields and related fields)store (bool) – whether the field is stored in database (default:
True,Falsefor computed fields)group_operator (str) –
aggregate function used by
read_group()when grouping on this field.Supported aggregate functions are:
array_agg: values, including nulls, concatenated into an arraycount: number of rowscount_distinct: number of distinct rowsbool_and: true if all values are true, otherwise falsebool_or: true if at least one value is true, otherwise falsemax: maximum value of all valuesmin: minimum value of all valuesavg: the average (arithmetic mean) of all valuessum: sum of all values
group_expand (str) –
function used to expand read_group results when grouping on the current field.
@api.model def _read_group_selection_field(self, values, domain, order): return ['choice1', 'choice2', ...] # available selection choices. @api.model def _read_group_many2one_field(self, records, domain, order): return records + self.search([custom_domain])
Computed Fields
- Parameters
compute (str) –
name of a method that computes the field
See also
compute_sudo (bool) – whether the field should be recomputed as superuser to bypass access rights (by default
Truefor stored fields,Falsefor non stored fields)inverse (str) – name of a method that inverses the field (optional)
search (str) – name of a method that implement search on the field (optional)
related (str) –
sequence of field names
See also
Basic Fields¶
- class flectra.fields.Char[source]¶
Basic string field, can be length-limited, usually displayed as a single-line string in clients.
- Parameters
size (int) – the maximum size of values stored for that field
trim (bool) – states whether the value is trimmed or not (by default,
True). Note that the trim operation is applied only by the web client.translate (bool or callable) – enable the translation of the field’s values; use
translate=Trueto translate field values as a whole;translatemay also be a callable such thattranslate(callback, value)translatesvalueby usingcallback(term)to retrieve the translation of terms.
- class flectra.fields.Float[source]¶
Encapsulates a
float.The precision digits are given by the (optional)
digitsattribute.- Parameters
digits (tuple(int,int) or str) – a pair (total, decimal) or a string referencing a
DecimalPrecisionrecord name.
When a float is a quantity associated with an unit of measure, it is important to use the right tool to compare or round values with the correct precision.
The Float class provides some static methods for this purpose:
round()to round a float with the given precision.is_zero()to check if a float equals zero at the given precision.compare()to compare two floats at the given precision.Example
To round a quantity with the precision of the unit of mesure:
fields.Float.round(self.product_uom_qty, precision_rounding=self.product_uom_id.rounding)
To check if the quantity is zero with the precision of the unit of mesure:
fields.Float.is_zero(self.product_uom_qty, precision_rounding=self.product_uom_id.rounding)
To compare two quantities:
field.Float.compare(self.product_uom_qty, self.qty_done, precision_rounding=self.product_uom_id.rounding)
The compare helper uses the __cmp__ semantics for historic purposes, therefore the proper, idiomatic way to use this helper is like so:
if result == 0, the first and second floats are equal if result < 0, the first float is lower than the second if result > 0, the first float is greater than the second
Advanced Fields¶
- class flectra.fields.Binary[source]¶
Encapsulates a binary content (e.g. a file).
- Parameters
attachment (bool) – whether the field should be stored as
ir_attachmentor in a column of the model’s table (default:True).
- class flectra.fields.Html[source]¶
Encapsulates an html code content.
- Parameters
sanitize (bool) – whether value must be sanitized (default:
True)sanitize_tags (bool) – whether to sanitize tags (only a white list of attributes is accepted, default:
True)sanitize_attributes (bool) – whether to sanitize attributes (only a white list of attributes is accepted, default:
True)sanitize_style (bool) – whether to sanitize style attributes (default:
False)strip_style (bool) – whether to strip style attributes (removed and therefore not sanitized, default:
False)strip_classes (bool) – whether to strip classes attributes (default:
False)
- class flectra.fields.Image[source]¶
Encapsulates an image, extending
Binary.If image size is greater than the
max_width/max_heightlimit of pixels, the image will be resized to the limit by keeping aspect ratio.- Parameters
max_width (int) – the maximum width of the image (default:
0, no limit)max_height (int) – the maximum height of the image (default:
0, no limit)verify_resolution (bool) – whether the image resolution should be verified to ensure it doesn’t go over the maximum image resolution (default:
True). Seeflectra.tools.image.ImageProcessfor maximum image resolution (default:45e6).
Note
If no
max_width/max_heightis specified (or is set to 0) andverify_resolutionis False, the field content won’t be verified at all and aBinaryfield should be used.
- class flectra.fields.Monetary[source]¶
Encapsulates a
floatexpressed in a givenres_currency.The decimal precision and currency symbol are taken from the
currency_fieldattribute.
- class flectra.fields.Selection[source]¶
Encapsulates an exclusive choice between different values.
- Parameters
selection (list(tuple(str,str)) or callable or str) – specifies the possible values for this field. It is given as either a list of pairs
(value, label), or a model method, or a method name.selection_add (list(tuple(str,str))) –
provides an extension of the selection in the case of an overridden field. It is a list of pairs
(value, label)or singletons(value,), where singleton values must appear in the overridden selection. The new values are inserted in an order that is consistent with the overridden selection and this list:selection = [('a', 'A'), ('b', 'B')] selection_add = [('c', 'C'), ('b',)] > result = [('a', 'A'), ('c', 'C'), ('b', 'B')]
ondelete –
provides a fallback mechanism for any overridden field with a selection_add. It is a dict that maps every option from the selection_add to a fallback action.
This fallback action will be applied to all records whose selection_add option maps to it.
- The actions can be any of the following:
’set null’ – the default, all records with this option will have their selection value set to False.
’cascade’ – all records with this option will be deleted along with the option itself.
’set default’ – all records with this option will be set to the default of the field definition
<callable> – a callable whose first and only argument will be the set of records containing the specified Selection option, for custom processing
The attribute
selectionis mandatory except in the case ofrelatedor extended fields.
- class flectra.fields.Text[source]¶
Very similar to
Charbut used for longer contents, does not have a size and usually displayed as a multiline text box.- Parameters
translate (bool or callable) – enable the translation of the field’s values; use
translate=Trueto translate field values as a whole;translatemay also be a callable such thattranslate(callback, value)translatesvalueby usingcallback(term)to retrieve the translation of terms.
Date(time) Fields¶
Dates and Datetimes
are very important fields in any kind of business application.
Their misuse can create invisible yet painful bugs, this section
aims to provide Flectra developers with the knowledge required
to avoid misusing these fields.
When assigning a value to a Date/Datetime field, the following options are valid:
A
dateordatetimeobject.A string in the proper server format:
FalseorNone.
The Date and Datetime fields class have helper methods to attempt conversion into a compatible type:
to_date()will convert to adatetime.dateto_datetime()will convert to adatetime.datetime.
Example
To parse date/datetimes coming from external sources:
fields.Date.to_date(self._context.get('date_from'))
Date / Datetime comparison best practices:
Date fields can only be compared to date objects.
Datetime fields can only be compared to datetime objects.
Warning
Strings representing dates and datetimes can be compared between each other, however the result may not be the expected result, as a datetime string will always be greater than a date string, therefore this practice is heavily discouraged.
Common operations with dates and datetimes such as addition, substraction or
fetching the start/end of a period are exposed through both
Date and Datetime.
These helpers are also available by importing flectra.tools.date_utils.
Note
Timezones
Datetime fields are stored as timestamp without timezone columns in the database and are stored
in the UTC timezone. This is by design, as it makes the Flectra database independent from the timezone
of the hosting server system. Timezone conversion is managed entirely by the client side.
- class flectra.fields.Date[source]¶
Encapsulates a python
dateobject.- static add(value, *args, **kwargs)[source]¶
Return the sum of
valueand arelativedelta.- Parameters
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- Returns
the resulting date/datetime.
- static context_today(record, timestamp=None)[source]¶
Return the current date as seen in the client’s timezone in a format fit for date fields.
Note
This method may be used to compute default values.
- Parameters
record – recordset from which the timezone will be obtained.
timestamp (datetime) – optional datetime value to use instead of the current date and time (must be a datetime, regular dates can’t be converted between timezones).
- Return type
date
- static end_of(value, granularity)[source]¶
Get end of a time period from a date or a datetime.
- Parameters
value – initial date or datetime.
granularity – Type of period in string, can be year, quarter, month, week, day or hour.
- Returns
A date/datetime object corresponding to the start of the specified period.
- static start_of(value, granularity)[source]¶
Get start of a time period from a date or a datetime.
- Parameters
value – initial date or datetime.
granularity – type of period in string, can be year, quarter, month, week, day or hour.
- Returns
a date/datetime object corresponding to the start of the specified period.
- static subtract(value, *args, **kwargs)[source]¶
Return the difference between
valueand arelativedelta.- Parameters
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- Returns
the resulting date/datetime.
- static to_date(value)[source]¶
Attempt to convert
valueto adateobject.Warning
If a datetime object is given as value, it will be converted to a date object and all datetime-specific information will be lost (HMS, TZ, …).
- class flectra.fields.Datetime[source]¶
Encapsulates a python
datetimeobject.- static add(value, *args, **kwargs)[source]¶
Return the sum of
valueand arelativedelta.- Parameters
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- Returns
the resulting date/datetime.
- static context_timestamp(record, timestamp)[source]¶
Return the given timestamp converted to the client’s timezone.
Note
This method is not meant for use as a default initializer, because datetime fields are automatically converted upon display on client side. For default values,
now()should be used instead.- Parameters
record – recordset from which the timezone will be obtained.
timestamp (datetime) – naive datetime value (expressed in UTC) to be converted to the client timezone.
- Returns
timestamp converted to timezone-aware datetime in context timezone.
- Return type
datetime
- static end_of(value, granularity)[source]¶
Get end of a time period from a date or a datetime.
- Parameters
value – initial date or datetime.
granularity – Type of period in string, can be year, quarter, month, week, day or hour.
- Returns
A date/datetime object corresponding to the start of the specified period.
- static now(*args)[source]¶
Return the current day and time in the format expected by the ORM.
Note
This function may be used to compute default values.
- static start_of(value, granularity)[source]¶
Get start of a time period from a date or a datetime.
- Parameters
value – initial date or datetime.
granularity – type of period in string, can be year, quarter, month, week, day or hour.
- Returns
a date/datetime object corresponding to the start of the specified period.
- static subtract(value, *args, **kwargs)[source]¶
Return the difference between
valueand arelativedelta.- Parameters
value – initial date or datetime.
args – positional args to pass directly to
relativedelta.kwargs – keyword args to pass directly to
relativedelta.
- Returns
the resulting date/datetime.
Relational Fields¶
- class flectra.fields.Many2one[source]¶
The value of such a field is a recordset of size 0 (no record) or 1 (a single record).
- Parameters
comodel_name (str) – name of the target model
Mandatoryexcept for related or extended fields.domain – an optional domain to set on candidate values on the client side (domain or string)
context (dict) – an optional context to use on the client side when handling that field
ondelete (str) – what to do when the referred record is deleted; possible values are:
'set null','restrict','cascade'auto_join (bool) – whether JOINs are generated upon search through that field (default:
False)delegate (bool) – set it to
Trueto make fields of the target model accessible from the current model (corresponds to_inherits)check_company (bool) – Mark the field to be verified in
_check_company(). Add a default company domain depending on the field attributes.
- class flectra.fields.One2many[source]¶
One2many field; the value of such a field is the recordset of all the records in
comodel_namesuch that the fieldinverse_nameis equal to the current record.- Parameters
comodel_name (str) – name of the target model
inverse_name (str) – name of the inverse
Many2onefield incomodel_namedomain – an optional domain to set on candidate values on the client side (domain or string)
context (dict) – an optional context to use on the client side when handling that field
auto_join (bool) – whether JOINs are generated upon search through that field (default:
False)limit (int) – optional limit to use upon read
The attributes
comodel_nameandinverse_nameare mandatory except in the case of related fields or field extensions.
- class flectra.fields.Many2many[source]¶
Many2many field; the value of such a field is the recordset.
- Parameters
comodel_name – name of the target model (string) mandatory except in the case of related or extended fields
relation (str) – optional name of the table that stores the relation in the database
column1 (str) – optional name of the column referring to “these” records in the table
relationcolumn2 (str) – optional name of the column referring to “those” records in the table
relation
The attributes
relation,column1andcolumn2are optional. If not given, names are automatically generated from model names, providedmodel_nameandcomodel_nameare different!Note that having several fields with implicit relation parameters on a given model with the same comodel is not accepted by the ORM, since those field would use the same table. The ORM prevents two many2many fields to use the same relation parameters, except if
both fields use the same model, comodel, and relation parameters are explicit; or
at least one field belongs to a model with
_auto = False.
- Parameters
domain – an optional domain to set on candidate values on the client side (domain or string)
context (dict) – an optional context to use on the client side when handling that field
check_company (bool) – Mark the field to be verified in
_check_company(). Add a default company domain depending on the field attributes.limit (int) – optional limit to use upon read
Pseudo-relational fields¶
- class flectra.fields.Reference[source]¶
Pseudo-relational field (no FK in database).
The field value is stored as a
stringfollowing the pattern"res_model.res_id"in database.
- class flectra.fields.Many2oneReference[source]¶
Pseudo-relational field (no FK in database).
The field value is stored as an
integerid in database.Contrary to
Referencefields, the model has to be specified in aCharfield, whose name has to be specified in themodel_fieldattribute for the currentMany2oneReferencefield.
Computed Fields¶
Fields can be computed (instead of read straight from the database) using the
compute parameter. It must assign the computed value to the field. If
it uses the values of other fields, it should specify those fields using
depends().
from flectra import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
dependencies can be dotted paths when using sub-fields:
@api.depends('line_ids.value') def _compute_total(self): for record in self: record.total = sum(line.value for line in record.line_ids)
computed fields are not stored by default, they are computed and returned when requested. Setting
store=Truewill store them in the database and automatically enable searching.searching on a computed field can also be enabled by setting the
searchparameter. The value is a method name returning a Search domains.upper_name = field.Char(compute='_compute_upper', search='_search_upper') def _search_upper(self, operator, value): if operator == 'like': operator = 'ilike' return [('name', operator, value)]
The search method is invoked when processing domains before doing an actual search on the model. It must return a domain equivalent to the condition:
field operator value.
Computed fields are readonly by default. To allow setting values on a computed field, use the
inverseparameter. It is the name of a function reversing the computation and setting the relevant fields:document = fields.Char(compute='_get_document', inverse='_set_document') def _get_document(self): for record in self: with open(record.get_document_path) as f: record.document = f.read() def _set_document(self): for record in self: if not record.document: continue with open(record.get_document_path()) as f: f.write(record.document)
multiple fields can be computed at the same time by the same method, just use the same method on all fields and set all of them:
discount_value = fields.Float(compute='_apply_discount') total = fields.Float(compute='_apply_discount') @api.depends('value', 'discount') def _apply_discount(self): for record in self: # compute actual discount from discount percentage discount = record.value * record.discount record.discount_value = discount record.total = record.value - discount
Warning
While it is possible to use the same compute method for multiple fields, it is not recommended to do the same for the inverse method.
During the computation of the inverse, all fields that use said inverse are protected, meaning that they can’t be computed, even if their value is not in the cache.
If any of those fields is accessed and its value is not in cache,
the ORM will simply return a default value of False for these fields.
This means that the value of the inverse fields (other than the one
triggering the inverse method) may not give their correct value and
this will probably break the expected behavior of the inverse method.
Automatic fields¶
Access Log fields¶
These fields are automatically set and updated if
_log_access is enabled. It can be
disabled to avoid creating or updating those fields on tables for which they are
not useful.
By default, _log_access is set to the same value
as _auto
Warning
_log_access must be enabled on
TransientModel.
Reserved Field names¶
A few field names are reserved for pre-defined behaviors beyond that of automated fields. They should be defined on a model when the related behavior is desired:
- flectra.fields.name¶
default value for
_rec_name, used to display records in context where a representative “naming” is necessary.
- flectra.fields.active¶
toggles the global visibility of the record, if
activeis set toFalsethe record is invisible in most searches and listing.
- flectra.fields.parent_id¶
default_value of
_parent_name, used to organize records in a tree structure and enables thechild_ofandparent_ofoperators in domains.
- flectra.fields.parent_path¶
When
_parent_storeis set to True, used to store a value reflecting the tree structure of_parent_name, and to optimize the operatorschild_ofandparent_ofin search domains. It must be declared withindex=Truefor proper operation.
- flectra.fields.company_id¶
Main field name used for Flectra multi-company behavior.
Used by
:meth:~flectra.models._check_companyto check multi company consistency. Defines whether a record is shared between companies (no value) or only accessible by the users of a given company.Many2one:type:res_company
Recordsets¶
Interactions with models and records are performed through recordsets, an ordered collection of records of the same model.
Warning
Contrary to what the name implies, it is currently possible for recordsets to contain duplicates. This may change in the future.
Methods defined on a model are executed on a recordset, and their self is
a recordset:
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self can be anything between 0 records and all records in the
# database
self.do_operation()
Iterating on a recordset will yield new sets of a single record (“singletons”), much like iterating on a Python string yields strings of a single characters:
def do_operation(self):
print(self) # => a.model(1, 2, 3, 4, 5)
for record in self:
print(record) # => a.model(1), then a.model(2), then a.model(3), ...
Field access¶
Recordsets provide an “Active Record” interface: model fields can be read and written directly from the record as attributes.
Note
When accessing non-relational fields on a recordset of potentially multiple
records, use mapped():
total_qty = sum(self.mapped('qty'))
Field values can also be accessed like dict items, which is more elegant and
safer than getattr() for dynamic field names.
Setting a field’s value triggers an update to the database:
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
>>> field = "name"
>>> record[field]
Bob
Warning
Trying to read a field on multiple records will raise an error for non relational fields.
Accessing a relational field (Many2one,
One2many, Many2many)
always returns a recordset, empty if the field is not set.
Record cache and prefetching¶
Flectra maintains a cache for the fields of the records, so that not every field access issues a database request, which would be terrible for performance. The following example queries the database only for the first statement:
record.name # first access reads value from database
record.name # second access gets value from cache
To avoid reading one field on one record at a time, Flectra prefetches records and fields following some heuristics to get good performance. Once a field must be read on a given record, the ORM actually reads that field on a larger recordset, and stores the returned values in cache for later use. The prefetched recordset is usually the recordset from which the record comes by iteration. Moreover, all simple stored fields (boolean, integer, float, char, text, date, datetime, selection, many2one) are fetched altogether; they correspond to the columns of the model’s table, and are fetched efficiently in the same query.
Consider the following example, where partners is a recordset of 1000
records. Without prefetching, the loop would make 2000 queries to the database.
With prefetching, only one query is made:
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
The prefetching also works on secondary records: when relational fields are read, their values (which are records) are subscribed for future prefetching. Accessing one of those secondary records prefetches all secondary records from the same model. This makes the following example generate only two queries, one for partners and one for countries:
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
Method decorators¶
The Flectra API module defines Flectra Environments and method decorators.
- flectra.api.autovacuum(method)[source]¶
Decorate a method so that it is called by the daily vacuum cron job (model
ir.autovacuum). This is typically used for garbage-collection-like tasks that do not deserve a specific cron job.
- flectra.api.constrains(*args)[source]¶
Decorate a constraint checker.
Each argument must be a field name used in the check:
@api.constrains('name', 'description') def _check_description(self): for record in self: if record.name == record.description: raise ValidationError("Fields name and description must be different")
Invoked on the records on which one of the named fields has been modified.
Should raise
ValidationErrorif the validation failed.Warning
@constrainsonly supports simple field names, dotted names (fields of relational fields e.g.partner_id.customer) are not supported and will be ignored.@constrainswill be triggered only if the declared fields in the decorated method are included in thecreateorwritecall. It implies that fields not present in a view will not trigger a call during a record creation. A override ofcreateis necessary to make sure a constraint will always be triggered (e.g. to test the absence of value).
- flectra.api.depends(*args)[source]¶
Return a decorator that specifies the field dependencies of a “compute” method (for new-style function fields). Each argument must be a string that consists in a dot-separated sequence of field names:
pname = fields.Char(compute='_compute_pname') @api.depends('partner_id.name', 'partner_id.is_company') def _compute_pname(self): for record in self: if record.partner_id.is_company: record.pname = (record.partner_id.name or "").upper() else: record.pname = record.partner_id.name
One may also pass a single function as argument. In that case, the dependencies are given by calling the function with the field’s model.
- flectra.api.depends_context(*args)[source]¶
Return a decorator that specifies the context dependencies of a non-stored “compute” method. Each argument is a key in the context’s dictionary:
price = fields.Float(compute='_compute_product_price') @api.depends_context('pricelist') def _compute_product_price(self): for product in self: if product.env.context.get('pricelist'): pricelist = self.env['product.pricelist'].browse(product.env.context['pricelist']) else: pricelist = self.env['product.pricelist'].get_default_pricelist() product.price = pricelist.get_products_price(product).get(product.id, 0.0)
All dependencies must be hashable. The following keys have special support:
company(value in context or current company id),uid(current user id and superuser flag),active_test(value in env.context or value in field.context).
- flectra.api.model(method)[source]¶
Decorate a record-style method where
selfis a recordset, but its contents is not relevant, only the model is. Such a method:@api.model def method(self, args): ...
- flectra.api.model_create_multi(method)[source]¶
Decorate a method that takes a list of dictionaries and creates multiple records. The method may be called with either a single dict or a list of dicts:
record = model.create(vals) records = model.create([vals, ...])
- flectra.api.onchange(*args)[source]¶
Return a decorator to decorate an onchange method for given fields.
In the form views where the field appears, the method will be called when one of the given fields is modified. The method is invoked on a pseudo-record that contains the values present in the form. Field assignments on that record are automatically sent back to the client.
Each argument must be a field name:
@api.onchange('partner_id') def _onchange_partner(self): self.message = "Dear %s" % (self.partner_id.name or "")
return { 'warning': {'title': "Warning", 'message': "What is this?", 'type': 'notification'}, }
If the type is set to notification, the warning will be displayed in a notification. Otherwise it will be displayed in a dialog as default.
Warning
@onchangeonly supports simple field names, dotted names (fields of relational fields e.g.partner_id.tz) are not supported and will be ignoredDanger
Since
@onchangereturns a recordset of pseudo-records, calling any one of the CRUD methods (create(),read(),write(),unlink()) on the aforementioned recordset is undefined behaviour, as they potentially do not exist in the database yet.Instead, simply set the record’s field like shown in the example above or call the
update()method.Warning
It is not possible for a
one2manyormany2manyfield to modify itself via onchange. This is a webclient limitation - see #2693.
- flectra.api.returns(model, downgrade=None, upgrade=None)[source]¶
Return a decorator for methods that return instances of
model.- Parameters
model – a model name, or
'self'for the current modeldowngrade – a function
downgrade(self, value, *args, **kwargs)to convert the record-stylevalueto a traditional-style outputupgrade – a function
upgrade(self, value, *args, **kwargs)to convert the traditional-stylevalueto a record-style output
The arguments
self,*argsand**kwargsare the ones passed to the method in the record-style.The decorator adapts the method output to the api style:
id,idsorFalsefor the traditional style, and recordset for the record style:@model @returns('res.partner') def find_partner(self, arg): ... # return some record # output depends on call style: traditional vs record style partner_id = model.find_partner(cr, uid, arg, context=context) # recs = model.browse(cr, uid, ids, context) partner_record = recs.find_partner(arg)
Note that the decorated method must satisfy that convention.
Those decorators are automatically inherited: a method that overrides a decorated existing method will be decorated with the same
@returns(model).
Environment¶
The Environment stores various contextual data used by
the ORM: the database cursor (for database queries), the current user
(for access rights checking) and the current context (storing arbitrary
metadata). The environment also stores caches.
All recordsets have an environment, which is immutable, can be accessed
using env and gives access to:
the current user (
user)the cursor (
cr)the superuser flag (
su)or the context (
context)
>>> records.env
<Environment object ...>
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...)
When creating a recordset from an other recordset, the environment is inherited. The environment can be used to get an empty recordset in an other model, and query that model:
>>> self.env['res.partner']
res.partner()
>>> self.env['res.partner'].search([['is_company', '=', True], ['customer', '=', True]])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
- Environment.ref(xml_id, raise_if_not_found=True)[source]¶
Return the record corresponding to the given
xml_id.
- Environment.user¶
Return the current user (as an instance).
- Return type
res_users
- Environment.company¶
Return the current company (as an instance).
If not specified in the context (
allowed_company_ids), fallback on current user main company.- Raises
AccessError – invalid or unauthorized
allowed_company_idscontext key content.- Returns
current company (default=`self.user.company_id`)
- Return type
res.company
Warning
No sanity checks applied in sudo mode ! When in sudo mode, a user can access any company, even if not in his allowed companies.
This allows to trigger inter-company modifications, even if the current user doesn’t have access to the targeted company.
- Environment.companies¶
Return a recordset of the enabled companies by the user.
If not specified in the context(
allowed_company_ids), fallback on current user companies.- Raises
AccessError – invalid or unauthorized
allowed_company_idscontext key content.- Returns
current companies (default=`self.user.company_ids`)
- Return type
res.company
Warning
No sanity checks applied in sudo mode ! When in sudo mode, a user can access any company, even if not in his allowed companies.
This allows to trigger inter-company modifications, even if the current user doesn’t have access to the targeted company.
Altering the environment¶
- Model.with_context([context][, **overrides]) records[source]¶
Returns a new version of this recordset attached to an extended context.
The extended context is either the provided
contextin whichoverridesare merged or the current context in whichoverridesare merged e.g.:# current context is {'key1': True} r2 = records.with_context({}, key2=True) # -> r2._context is {'key2': True} r2 = records.with_context(key2=True) # -> r2._context is {'key1': True, 'key2': True}
- Model.with_user(user)[source]¶
Return a new version of this recordset attached to the given user, in non-superuser mode, unless
useris the superuser (by convention, the superuser is always in superuser mode.)
- Model.with_company(company)[source]¶
Return a new version of this recordset with a modified context, such that:
result.env.company = company result.env.companies = self.env.companies | company
- Parameters
company (
res_companyor int) – main company of the new environment.
Warning
When using an unauthorized company for current user, accessing the company(ies) on the environment may trigger an AccessError if not done in a sudoed environment.
- Model.with_env(env)[source]¶
Return a new version of this recordset attached to the provided environment.
- Parameters
env (
Environment) –
Warning
The new environment will not benefit from the current environment’s data cache, so later data access may incur extra delays while re-fetching from the database. The returned recordset has the same prefetch object as
self.
- Model.sudo([flag=True])[source]¶
Returns a new version of this recordset with superuser mode enabled or disabled, depending on
flag. The superuser mode does not change the current user, and simply bypasses access rights checks.Warning
Using
sudocould cause data access to cross the boundaries of record rules, possibly mixing records that are meant to be isolated (e.g. records from different companies in multi-company environments).It may lead to un-intuitive results in methods which select one record among many - for example getting the default company, or selecting a Bill of Materials.
Note
Because the record rules and access control will have to be re-evaluated, the new recordset will not benefit from the current environment’s data cache, so later data access may incur extra delays while re-fetching from the database. The returned recordset has the same prefetch object as
self.
SQL Execution¶
The cr attribute on environments is the
cursor for the current database transaction and allows executing SQL directly,
either for queries which are difficult to express using the ORM (e.g. complex
joins) or for performance reasons:
self.env.cr.execute("some_sql", params)
Because models use the same cursor and the Environment
holds various caches, these caches must be invalidated when altering the
database in raw SQL, or further uses of models may become incoherent. It is
necessary to clear caches when using CREATE, UPDATE or DELETE in
SQL, but not SELECT (which simply reads the database).
Note
Clearing caches can be performed using the
invalidate_cache() method.
- Model.invalidate_cache(fnames=None, ids=None)[source]¶
Invalidate the record caches after some records have been modified. If both
fnamesandidsareNone, the whole cache is cleared.- Parameters
fnames – the list of modified fields, or
Nonefor all fieldsids – the list of modified record ids, or
Nonefor all
Warning
Executing raw SQL bypasses the ORM, and by consequent, Flectra security rules. Please make sure your queries are sanitized when using user input and prefer using ORM utilities if you don’t really need to use SQL queries.
Common ORM methods¶
Create/update¶
- Model.create(vals_list) records[source]¶
Creates new records for the model.
The new records are initialized using the values from the list of dicts
vals_list, and if necessary those fromdefault_get().- Parameters
vals_list (list) –
values for the model’s fields, as a list of dictionaries:
[{'field_name': field_value, ...}, ...]
For backward compatibility,
vals_listmay be a dictionary. It is treated as a singleton list[vals], and a single record is returned.see
write()for details- Returns
the created records
- Raises
if user has no create rights on the requested object
if user tries to bypass access rules for create on the requested object
ValidationError – if user tries to enter invalid value for a field that is not in selection
UserError – if a loop would be created in a hierarchy of objects a result of the operation (such as setting an object as its own parent)
- Model.copy(default=None)[source]¶
Duplicate record
selfupdating it with default values- Parameters
default (dict) – dictionary of field values to override in the original values of the copied record, e.g:
{'field_name': overridden_value, ...}- Returns
new record
- Model.default_get(fields_list) default_values[source]¶
Return default values for the fields in
fields_list. Default values are determined by the context, user defaults, and the model itself.- Parameters
fields_list (list) – names of field whose default is requested
- Returns
a dictionary mapping field names to their corresponding default values, if they have a default value.
- Return type
Note
Unrequested defaults won’t be considered, there is no need to return a value for fields whose names are not in
fields_list.
- Model.name_create(name) record[source]¶
Create a new record by calling
create()with only one value provided: the display name of the new record.The new record will be initialized with any default values applicable to this model, or provided through the context. The usual behavior of
create()applies.- Parameters
name – display name of the record to create
- Return type
- Returns
the
name_get()pair value of the created record
- Model.write(vals)[source]¶
Updates all records in the current set with the provided values.
- Parameters
vals (dict) –
fields to update and the value to set on them e.g:
{'foo': 1, 'bar': "Qux"}
will set the field
footo1and the fieldbarto"Qux"if those are valid (otherwise it will trigger an error).- Raises
if user has no write rights on the requested object
if user tries to bypass access rules for write on the requested object
ValidationError – if user tries to enter invalid value for a field that is not in selection
UserError – if a loop would be created in a hierarchy of objects a result of the operation (such as setting an object as its own parent)
For numeric fields (
Integer,Float) the value should be of the corresponding typeFor
Selection, the value should match the selection values (generallystr, sometimesint)For
Many2one, the value should be the database identifier of the record to setOther non-relational fields use a string for value
Danger
for historical and compatibility reasons,
DateandDatetimefields use strings as values (written and read) rather thandateordatetime. These date strings are UTC-only and formatted according toflectra.tools.misc.DEFAULT_SERVER_DATE_FORMATandflectra.tools.misc.DEFAULT_SERVER_DATETIME_FORMATOne2manyandMany2manyuse a special “commands” format to manipulate the set of records stored in/associated with the field.This format is a list of triplets executed sequentially, where each triplet is a command to execute on the set of records. Not all commands apply in all situations. Possible commands are:
(0, 0, values)adds a new record created from the provided
valuedict.(1, id, values)updates an existing record of id
idwith the values invalues. Can not be used increate().(2, id, 0)removes the record of id
idfrom the set, then deletes it (from the database). Can not be used increate().(3, id, 0)removes the record of id
idfrom the set, but does not delete it. Can not be used increate().(4, id, 0)adds an existing record of id
idto the set.(5, 0, 0)removes all records from the set, equivalent to using the command
3on every record explicitly. Can not be used increate().(6, 0, ids)replaces all existing records in the set by the
idslist, equivalent to using the command5followed by a command4for eachidinids.
- Model.flush(fnames=None, records=None)[source]¶
Process all the pending computations (on all models), and flush all the pending updates to the database.
- Parameters
(list<str>) (fnames) – list of field names to flush. If given, limit the processing to the given fields of the current model.
(Model) (records) – if given (together with
fnames), limit the processing to the given records.
Search/Read¶
- Model.browse([ids]) records[source]¶
Returns a recordset for the ids provided as parameter in the current environment.
self.browse([7, 18, 12]) res.partner(7, 18, 12)
- Model.search(args[, offset=0][, limit=None][, order=None][, count=False])[source]¶
Searches for records based on the
argssearch domain.- Parameters
args – A search domain. Use an empty list to match all records.
offset (int) – number of results to ignore (default: none)
limit (int) – maximum number of records to return (default: all)
order (str) – sort string
count (bool) – if True, only counts and returns the number of matching records (default: False)
- Returns
at most
limitrecords matching the search criteria- Raises
if user tries to bypass access rules for read on the requested object.
- Model.search_count(args) int[source]¶
Returns the number of records in the current model matching the provided domain.
- Model.name_search(name='', args=None, operator='ilike', limit=100) records[source]¶
Search for records that have a display name matching the given
namepattern when compared with the givenoperator, while also matching the optional search domain (args).This is used for example to provide suggestions based on a partial value for a relational field. Sometimes be seen as the inverse function of
name_get(), but it is not guaranteed to be.This method is equivalent to calling
search()with a search domain based ondisplay_nameand thenname_get()on the result of the search.- Parameters
- Return type
- Returns
list of pairs
(id, text_repr)for all matching records.
- Model.read([fields])[source]¶
Reads the requested fields for the records in
self, low-level/RPC method. In Python code, preferbrowse().- Parameters
fields – list of field names to return (default is all fields)
- Returns
a list of dictionaries mapping field names to their values, with one dictionary per record
- Raises
AccessError – if user has no read rights on some of the given records
- Model.read_group(domain, fields, groupby, offset=0, limit=None, orderby=False, lazy=True)[source]¶
Get the list of records in list view grouped by the given
groupbyfields.- Parameters
domain (list) – A search domain. Use an empty list to match all records.
fields (list) – list of fields present in the list view specified on the object. Each element is either ‘field’ (field name, using the default aggregation), or ‘field:agg’ (aggregate field with aggregation function ‘agg’), or ‘name:agg(field)’ (aggregate field with ‘agg’ and return it as ‘name’). The possible aggregation functions are the ones provided by PostgreSQL (https://www.postgresql.org/docs/current/static/functions-aggregate.html) and ‘count_distinct’, with the expected meaning.
groupby (list) – list of groupby descriptions by which the records will be grouped. A groupby description is either a field (then it will be grouped by that field) or a string ‘field:groupby_function’. Right now, the only functions supported are ‘day’, ‘week’, ‘month’, ‘quarter’ or ‘year’, and they only make sense for date/datetime fields.
offset (int) – optional number of records to skip
limit (int) – optional max number of records to return
orderby (str) – optional
order byspecification, for overriding the natural sort ordering of the groups, see alsosearch()(supported only for many2one fields currently)lazy (bool) – if true, the results are only grouped by the first groupby and the remaining groupbys are put in the __context key. If false, all the groupbys are done in one call.
- Returns
list of dictionaries(one dictionary for each record) containing:
the values of fields grouped by the fields in
groupbyargument__domain: list of tuples specifying the search criteria
__context: dictionary with argument like
groupby
- Return type
[{‘field_name_1’: value, …]
- Raises
if user has no read rights on the requested object
if user tries to bypass access rules for read on the requested object
Fields/Views¶
- Model.fields_get([fields][, attributes])[source]¶
Return the definition of each field.
The returned value is a dictionary (indexed by field name) of dictionaries. The _inherits’d fields are included. The string, help, and selection (if present) attributes are translated.
- Parameters
allfields – list of fields to document, all if empty or not provided
attributes – list of description attributes to return for each field, all if empty or not provided
- Model.fields_view_get([view_id | view_type='form'])[source]¶
Get the detailed composition of the requested view like fields, model, view architecture
- Parameters
- Returns
composition of the requested view (including inherited views and extensions)
- Return type
- Raises
if the inherited view has unknown position to work with other than ‘before’, ‘after’, ‘inside’, ‘replace’
if some tag other than ‘position’ is found in parent view
Invalid ArchitectureError – if there is view type other than form, tree, calendar, search etc defined on the structure
Search domains¶
A domain is a list of criteria, each criterion being a triple (either a
list or a tuple) of (field_name, operator, value) where:
field_name(str)a field name of the current model, or a relationship traversal through a
Many2oneusing dot-notation e.g.'street'or'partner_id.country'
operator(str)an operator used to compare the
field_namewith thevalue. Valid operators are:=equals to
!=not equals to
>greater than
>=greater than or equal to
<less than
<=less than or equal to
=?unset or equals to (returns true if
valueis eitherNoneorFalse, otherwise behaves like=)=likematches
field_nameagainst thevaluepattern. An underscore_in the pattern stands for (matches) any single character; a percent sign%matches any string of zero or more characters.likematches
field_nameagainst the%value%pattern. Similar to=likebut wrapsvaluewith ‘%’ before matchingnot likedoesn’t match against the
%value%patternilikecase insensitive
likenot ilikecase insensitive
not like=ilikecase insensitive
=likeinis equal to any of the items from
value,valueshould be a list of itemsnot inis unequal to all of the items from
valuechild_ofis a child (descendant) of a
valuerecord (value can be either one item or a list of items).Takes the semantics of the model into account (i.e following the relationship field named by
_parent_name).parent_ofis a parent (ascendant) of a
valuerecord (value can be either one item or a list of items).Takes the semantics of the model into account (i.e following the relationship field named by
_parent_name).
valuevariable type, must be comparable (through
operator) to the named field.
Domain criteria can be combined using logical operators in prefix form:
'&'logical AND, default operation to combine criteria following one another. Arity 2 (uses the next 2 criteria or combinations).
'|'logical OR, arity 2.
'!'logical NOT, arity 1.
Note
Mostly to negate combinations of criteria Individual criterion generally have a negative form (e.g.
=->!=,<->>=) which is simpler than negating the positive.
Example
To search for partners named ABC, from belgium or germany, whose language is not english:
[('name','=','ABC'),
('language.code','!=','en_US'),
'|',('country_id.code','=','be'),
('country_id.code','=','de')]
This domain is interpreted as:
(name is 'ABC')
AND (language is NOT english)
AND (country is Belgium OR Germany)
Unlink¶
Record(set) information¶
- Model.ids¶
Return the list of actual record ids corresponding to
self.
- flectra.models.env¶
Returns the environment of the given recordset.
- Type
Environment
- Model.exists() records[source]¶
Returns the subset of records in
selfthat exist, and marks deleted records as such in cache. It can be used as a test on records:if record.exists(): ...
By convention, new records are returned as existing.
- Model.ensure_one()[source]¶
Verify that the current recorset holds a single record.
- Raises
flectra.exceptions.ValueError –
len(self) != 1
- Model.name_get() [id, name, ...][source]¶
Returns a textual representation for the records in
self. By default this is the value of thedisplay_namefield.
- Model.get_metadata()[source]¶
Return some metadata about the given records.
- Returns
list of ownership dictionaries for each requested record
- Return type
list of dictionaries with the following keys:
id: object id
create_uid: user who created the record
create_date: date when the record was created
write_uid: last user who changed the record
write_date: date of the last change to the record
xmlid: XML ID to use to refer to this record (if there is one), in format
module.namenoupdate: A boolean telling if the record will be updated or not
Operations¶
Recordsets are immutable, but sets of the same model can be combined using various set operations, returning new recordsets.
record in setreturns whetherrecord(which must be a 1-element recordset) is present inset.record not in setis the inverse operationset1 <= set2andset1 < set2return whetherset1is a subset ofset2(resp. strict)set1 >= set2andset1 > set2return whetherset1is a superset ofset2(resp. strict)set1 | set2returns the union of the two recordsets, a new recordset containing all records present in either sourceset1 & set2returns the intersection of two recordsets, a new recordset containing only records present in both sourcesset1 - set2returns a new recordset containing only records ofset1which are not inset2
Recordsets are iterable so the usual Python tools are available for
transformation (map(), sorted(),
itertools.ifilter, …) however these return either a
list or an iterator, removing the ability to
call methods on their result, or to use set operations.
Recordsets therefore provide the following operations returning recordsets themselves (when possible):
Filter¶
- Model.filtered(func)[source]¶
Return the records in
selfsatisfyingfunc.- Parameters
func (callable or str) – a function or a dot-separated sequence of field names
- Returns
recordset of records satisfying func, may be empty.
# only keep records whose company is the current user's records.filtered(lambda r: r.company_id == user.company_id) # only keep records whose partner is a company records.filtered("partner_id.is_company")
Map¶
- Model.mapped(func)[source]¶
Apply
funcon all records inself, and return the result as a list or a recordset (iffuncreturn recordsets). In the latter case, the order of the returned recordset is arbitrary.- Parameters
func (callable or str) – a function or a dot-separated sequence of field names
- Returns
self if func is falsy, result of func applied to all
selfrecords.- Return type
list or recordset
# returns a list of summing two fields for each record in the set records.mapped(lambda r: r.field1 + r.field2)
The provided function can be a string to get field values:
# returns a list of names records.mapped('name') # returns a recordset of partners records.mapped('partner_id') # returns the union of all partner banks, with duplicates removed records.mapped('partner_id.bank_ids')
Note
Since V13, multi-relational field access is supported and works like a mapped call:
records.partner_id # == records.mapped('partner_id')
records.partner_id.bank_ids # == records.mapped('partner_id.bank_ids')
records.partner_id.mapped('name') # == records.mapped('partner_id.name')
Sort¶
Inheritance and extension¶
Flectra provides three different mechanisms to extend models in a modular way:
creating a new model from an existing one, adding new information to the copy but leaving the original module as-is
extending models defined in other modules in-place, replacing the previous version
delegating some of the model’s fields to records it contains
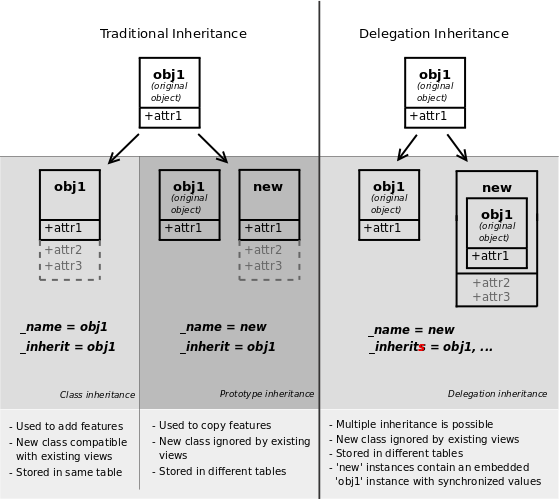
Classical inheritance¶
When using the _inherit and
_name attributes together, Flectra creates a new
model using the existing one (provided via
_inherit) as a base. The new model gets all the
fields, methods and meta-information (defaults & al) from its base.
class Inheritance0(models.Model):
_name = 'inheritance.0'
_description = 'Inheritance Zero'
name = fields.Char()
def call(self):
return self.check("model 0")
def check(self, s):
return "This is {} record {}".format(s, self.name)
class Inheritance1(models.Model):
_name = 'inheritance.1'
_inherit = 'inheritance.0'
_description = 'Inheritance One'
def call(self):
return self.check("model 1")
and using them:
a = env['inheritance.0'].create({'name': 'A'})
b = env['inheritance.1'].create({'name': 'B'})
a.call()
b.call()
will yield:
“This is model 0 record A” “This is model 1 record B”
the second model has inherited from the first model’s check method and its
name field, but overridden the call method, as when using standard
Python inheritance.
Extension¶
When using _inherit but leaving out
_name, the new model replaces the existing one,
essentially extending it in-place. This is useful to add new fields or methods
to existing models (created in other modules), or to customize or reconfigure
them (e.g. to change their default sort order):
class Extension0(models.Model):
_name = 'extension.0'
_description = 'Extension zero'
name = fields.Char(default="A")
class Extension1(models.Model):
_inherit = 'extension.0'
description = fields.Char(default="Extended")
record = env['extension.0'].create({})
record.read()[0]
will yield:
{'name': "A", 'description': "Extended"}
Note
It will also yield the various automatic fields unless they’ve been disabled
Delegation¶
The third inheritance mechanism provides more flexibility (it can be altered
at runtime) but less power: using the _inherits
a model delegates the lookup of any field not found on the current model
to “children” models. The delegation is performed via
Reference fields automatically set up on the parent
model.
The main difference is in the meaning. When using Delegation, the model has one instead of is one, turning the relationship in a composition instead of inheritance:
class Screen(models.Model):
_name = 'delegation.screen'
_description = 'Screen'
size = fields.Float(string='Screen Size in inches')
class Keyboard(models.Model):
_name = 'delegation.keyboard'
_description = 'Keyboard'
layout = fields.Char(string='Layout')
class Laptop(models.Model):
_name = 'delegation.laptop'
_description = 'Laptop'
_inherits = {
'delegation.screen': 'screen_id',
'delegation.keyboard': 'keyboard_id',
}
name = fields.Char(string='Name')
maker = fields.Char(string='Maker')
# a Laptop has a screen
screen_id = fields.Many2one('delegation.screen', required=True, ondelete="cascade")
# a Laptop has a keyboard
keyboard_id = fields.Many2one('delegation.keyboard', required=True, ondelete="cascade")
record = env['delegation.laptop'].create({
'screen_id': env['delegation.screen'].create({'size': 13.0}).id,
'keyboard_id': env['delegation.keyboard'].create({'layout': 'QWERTY'}).id,
})
record.size
record.layout
will result in:
13.0
'QWERTY'
and it’s possible to write directly on the delegated field:
record.write({'size':2.0})
Warning
when using delegation inheritance, methods are not inherited, only fields
Warning
_inheritsis more or less implemented, avoid it if you can;chained
_inheritsis essentially not implemented, we cannot guarantee anything on the final behavior.
Fields Incremental Definition¶
A field is defined as class attribute on a model class. If the model is extended, one can also extend the field definition by redefining a field with the same name and same type on the subclass. In that case, the attributes of the field are taken from the parent class and overridden by the ones given in subclasses.
For instance, the second class below only adds a tooltip on the field
state:
class First(models.Model):
_name = 'foo'
state = fields.Selection([...], required=True)
class Second(models.Model):
_inherit = 'foo'
state = fields.Selection(help="Blah blah blah")
Error management¶
The Flectra Exceptions module defines a few core exception types.
Those types are understood by the RPC layer. Any other exception type bubbling until the RPC layer will be treated as a ‘Server error’.
Note
If you consider introducing new exceptions,
check out the flectra.addons.test_exceptions module.
- exception flectra.exceptions.AccessDenied(message='Access Denied')[source]¶
Login/password error.
Note
No traceback.
Example
When you try to log with a wrong password.
- exception flectra.exceptions.AccessError(message)[source]¶
Access rights error.
Example
When you try to read a record that you are not allowed to.
- exception flectra.exceptions.CacheMiss(record, field)[source]¶
Missing value(s) in cache.
Example
When you try to read a value in a flushed cache.
- exception flectra.exceptions.MissingError(message)[source]¶
Missing record(s).
Example
When you try to write on a deleted record.
- exception flectra.exceptions.RedirectWarning(message, action, button_text, additional_context=None)[source]¶
Warning with a possibility to redirect the user instead of simply displaying the warning message.
- Parameters
message (str) – exception message and frontend modal content
action_id (int) – id of the action where to perform the redirection
button_text (str) – text to put on the button that will trigger the redirection.
additional_context (dict) – parameter passed to action_id. Can be used to limit a view to active_ids for example.